
Java中代码优化的30个小技巧
1.用String.format拼接字符串
String.format方法拼接url请求参数,日志打印等字符串。
但不建议在for循环中用它拼接字符串,因为它的执行效率,比使用+号拼接字符串,或者使用StringBuilder拼接字符串都要慢一些。
2.创建可缓冲的IO流
//尽量使用try-with-resources语句,可以在程序结束时自动关闭资源 |
使用缓冲流
File srcFile = new File("/Users/Documents/test1/1.txt"); |
3.减少循环次数
如果循环层级比较深,循环中套循环,可能会影响代码的执行效率。
如果有两层循环,如果userList和roleList数据比较多的话,需要循环遍历很多次,才能获取我们所需要的数据,非常消耗cpu资源。
如下代码所示:
//正常逻辑2层for循环处理 |
优化后的代码如下所示:
Map<Long, List<Role>> roleMap = roleList.stream().collect(Collectors.groupingBy(Role::getId)); |
优化思想就是减少循环次数,最简单的办法是,把第二层循环的集合变成map,这样可以直接通过key,获取想要的value数据。
虽说map的key存在hash冲突的情况,但遍历存放数据的链表或者红黑树的时间复杂度,比遍历整个list集合要小很多。
4.用完资源记得及时关闭
参考第二点尽量使用try-with-resources语句或者手动关闭资源
5.使用池技术
数据库连接池、线程池
6.消除if…else的锦囊妙计,反射时添加缓存
我们都知道通过反射创建对象实例,比使用new关键字要慢很多。
由此,不太建议在用户请求过来时,每次都通过反射实时创建实例。
有时候,为了代码的灵活性,又不得不用反射创建实例,这时该怎么办呢?
答:加缓存。
先看以下代码
publicinterface IPay { |
这里违法了设计模式六大原则的:开闭原则 和 单一职责原则。
开闭原则:对扩展开放,对修改关闭。就是说增加新功能要尽量少改动已有代码。
单一职责原则:顾名思义,要求逻辑尽量单一,不要太复杂,便于复用。
- 先创建一个注解
- 在所有的支付类上都加上该注解
- 增加最关键的类PayService2
/** |
PayService2类实现了ApplicationListener接口,这样在onApplicationEvent方法中,就可以拿到ApplicationContext的实例。这一步,其实是在spring容器启动的时候,spring通过反射我们处理好了。
我们再获取打了PayCode注解的类,放到一个map中,map中的key就是PayCode注解中定义的value,跟code参数一致,value是支付类的实例。
这样,每次就可以每次直接通过code获取支付类实例,而不用if…else判断了。如果要加新的支付方法,只需在支付类上面打上PayCode注解定义一个新的code即可。
注意:这种方式的code可以没有业务含义,可以是纯数字,只要不重复就行。
7.多线程处理
一句话把串行执行的接口变成并行执行;
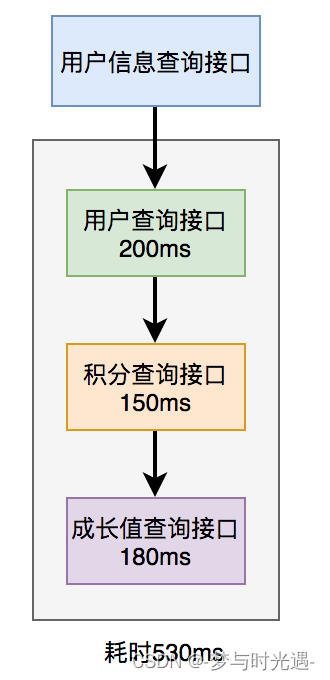
并行执行
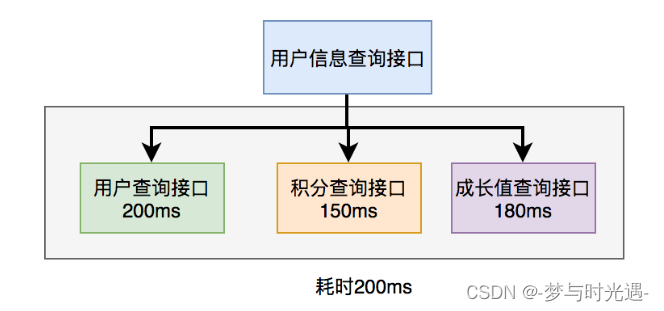
在java8之前可以通过实现Callable接口,获取线程返回结果。
java8以后通过CompleteFuture类实现该功能。我们这里以CompleteFuture为例:
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException { |
8.懒加载
有时候,创建对象是一个非常耗时的操作,特别是在该对象的创建过程中,还需要创建很多其他的对象时。
我们以单例模式为例。
在介绍单例模式的时候,必须要先介绍它的两种非常著名的实现方式:饿汉模式 和 懒汉模式。
8.1 饿汉模式
实例在初始化的时候就已经建好了,不管你有没有用到,先建好了再说。具体代码如下:
public class SimpleSingleton { |
使用饿汉模式的好处是:没有线程安全的问题,但带来的坏处也很明显。
8.2 懒汉模式
顾名思义就是实例在用到的时候才去创建,”比较懒”,用的时候才去检查有没有实例,如果有则返回,没有则新建。具体代码如下:
public class SimpleSingleton2 { |
示例中的INSTANCE对象一开始是空的,在调用getInstance方法才会真正实例化。
懒汉模式相对于饿汉模式,没有提前实例化对象,在真正使用的时候再实例化,在实例化对象的阶段效率更高一些。
除了单例模式之外,懒加载的思想,使用比较多的可能是:
spring的@Lazy注解。在spring容器启动的时候,不会调用其getBean方法初始化实例。
mybatis的懒加载。在mybatis做级联查询的时候,比如查用户的同时需要查角色信息。如果用了懒加载,先只查用户信息,真正使用到角色了,才取查角色信息。
9.初始化集合时指定大小
在创建集合时指定了大小,比没有指定大小,添加10万个元素的效率提升了一倍。
如果你看过ArrayList源码,你就会发现它的默认大小是10,如果添加元素超过了一定的阀值,会按1.5倍的大小扩容。
你想想,如果装10万条数据,需要扩容多少次呀?而每次扩容都需要不停的复制元素,从老集合复制到新集合中,需要浪费多少时间呀。
//示例 |
10.不要满屏try…catch异常
可以使用全局异常处理:RestControllerAdvice
|
11.位运算效率更高
12.巧用第三方工具类
如果你引入com.google.guava的pom文件,会获得很多好用的小工具。这里推荐一款com.google.common.collect包下的集合工具:Lists。
//guava提供的字符串工具类 |
13.用同步代码块代替同步方法
在某些业务场景中,为了防止多个线程并发修改某个共享数据,造成数据异常。
为了解决并发场景下,多个线程同时修改数据,造成数据不一致的情况。通常情况下,我们会:加锁。
但如果锁加得不好,导致锁的粒度太粗,也会非常影响接口性能。
在java中提供了synchronized关键字给我们的代码加锁。
通常有两种写法:在方法上加锁 和 在代码块上加锁。
先看看如何在方法上加锁:
public synchronized doSave(String fileUrl) { |
这里加锁的目的是为了防止并发的情况下,创建了相同的目录,第二次会创建失败,影响业务功能。
但这种直接在方法上加锁,锁的粒度有点粗。因为doSave方法中的上传文件和发消息方法,是不需要加锁的。只有创建目录方法,才需要加锁。
我们都知道文件上传操作是非常耗时的,如果将整个方法加锁,那么需要等到整个方法执行完之后才能释放锁。显然,这会导致该方法的性能很差,变得得不偿失。
这时,我们可以改成在代码块上加锁了,具体代码如下:
public void doSave(String path,String fileUrl) { |
这样改造之后,锁的粒度一下子变小了,只有并发创建目录功能才加了锁。而创建目录是一个非常快的操作,即使加锁对接口的性能影响也不大。
最重要的是,其他的上传文件和发送消息功能,任然可以并发执行。
14.不用的数据及时清理
在Java中保证线程安全的技术有很多,可以使用synchroized、Lock等关键字给代码块加锁。
但是它们有个共同的特点,就是加锁会对代码的性能有一定的损耗。
其实,在jdk中还提供了另外一种思想即:用空间换时间。
没错,使用ThreadLocal类就是对这种思想的一种具体体现。
ThreadLocal为每个使用变量的线程提供了一个独立的变量副本,这样每一个线程都能独立地改变自己的副本,而不会影响其它线程所对应的副本。
ThreadLocal的用法大致是这样的:
先创建一个CurrentUser类,其中包含了ThreadLocal的逻辑。
public class CurrentUser {
private static final ThreadLocal<UserInfo> THREA_LOCAL = new ThreadLocal();
public static void set(UserInfo userInfo) {
THREA_LOCAL.set(userInfo);
}
public static UserInfo get() {
THREA_LOCAL.get();
}
public static void remove() {
THREA_LOCAL.remove();
}
}在业务代码中调用CurrentUser类。
public void doSamething(UserDto userDto) {
UserInfo userInfo = convert(userDto);
CurrentUser.set(userInfo);
...
//业务代码
UserInfo userInfo = CurrentUser.get();
...
}在业务代码的第一行,将userInfo对象设置到CurrentUser,这样在业务代码中,就能通过CurrentUser.get()获取到刚刚设置的userInfo对象。特别是对业务代码调用层级比较深的情况,这种用法非常有用,可以减少很多不必要传参。
但在高并发的场景下,这段代码有问题,只往ThreadLocal存数据,数据用完之后并没有及时清理。
ThreadLocal即使使用了WeakReference(弱引用)也可能会存在
内存泄露问题,因为 entry对象中只把key(即threadLocal对象)设置成了弱引用,但是value值没有。那么,如何解决这个问题呢?
public void doSamething(UserDto userDto) { |
需要在finally代码块中,调用remove方法清理没用的数据。
15.用equals方法比较是否相等
16.避免创建大集合
尽量分页处理
17.状态用枚举
public enum OrderStatusEnum { |
而且使用枚举的好处是:
代码的可读性变强了,不同的状态,有不同的枚举进行统一管理和维护。
枚举是天然单例的,可以直接使用==号进行比较。
code和message可以成对出现,比较容易相关转换。
枚举可以消除if…else过多问题。
18.把固定值定义成静态常量
使用static final关键字修饰静态常量,static表示静态的意思,即类变量,而final表示不允许修改。
两个关键字加在一起,告诉Java虚拟机这种变量,在内存中只有一份,在全局上是唯一的,不能修改,也就是静态常量。
19.避免大事务
很多小伙伴在使用spring框架开发项目时,为了方便,喜欢使用@Transactional注解提供事务功能。
没错,使用@Transactional注解这种声明式事务的方式提供事务功能,确实能少写很多代码,提升开发效率。
但也容易造成大事务,引发其他的问题。
下面用一张图看看大事务引发的问题。
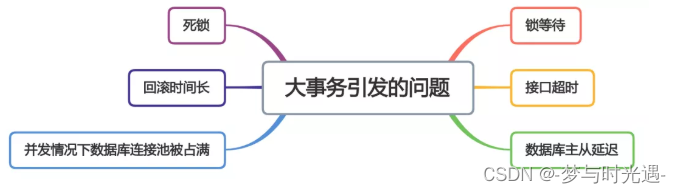
从图中能够看出,大事务问题可能会造成接口超时,对接口的性能有直接的影响。
我们该如何优化大事务呢?
少用@Transactional注解
将查询(select)方法放到事务外
事务中避免远程调用
事务中避免一次性处理太多数据
有些功能可以非事务执行
有些功能可以异步处理
大家可以参考关于大事务的这篇文章《让人头痛的大事务问题到底要如何解决?》
20.消除过长的if…else
更详细的内容可以看看这篇文章《消除if…else是9条锦囊妙计》
21.防止死循环
22.注意BigDecimal的坑
通常我们会把一些小数类型的字段(比如:金额),定义成BigDecimal,而不是Double,避免丢失精度问题。
常识告诉我们使用BigDecimal能避免丢失精度。
但是使用BigDecimal能避免丢失精度吗?
答案是否定的。
为什么?
BigDecimal amount1 = new BigDecimal(0.02); |
结果:
0.0099999999999999984734433411404097569175064563751220703125
不科学呀,为啥还是丢失精度了?
使用BigDecimal构造函数初始化对象,也会丢失精度。
那么,如何才能不丢失精度呢?
BigDecimal amount1 = BigDecimal.valueOf(0.02); |
23.尽可能复用代码
24.foreach循环中不remove元素
循环有很多种写法,比如:while、for、foreach等。
public class Test2 { |
这种在foreach循环中调用remove方法删除元素,可能会报ConcurrentModificationException异常。
如果想在遍历集合时,删除其中的元素,可以用for循环,例如:
List<String> list = Lists.newArrayList("a","b","c"); |
25.避免随意打印日志
使用isDebugEnabled判断一下,如果当前的日志级别是debug才打印日志。生产环境默认日志级别是info,在有些紧急情况下,把某个接口或者方法的日志级别改成debug,打印完我们需要的日志后,又调整回去。
方便我们定位问题,又不会产生大量的垃圾日志,一举两得
|
26.比较时把常量写前面
private static final String FOUND_NAME = "苏三"; |
在使用equals做比较时,尽量将常量写在前面,即equals方法的左边。
这样即使user.getName()返回的数据为null,equals方法会直接返回false,而不再是报空指针异常。
27.名称要见名知意
28.SimpleDateFormat线程不安全
使用java8的DateTimeFormatter类。
29.少用Executors创建线程池
我们都知道JDK5之后,提供了ThreadPoolExecutor类,用它可以自定义线程池。
线程池的好处有很多,下面主要说说这3个方面。
降低资源消耗:避免了频繁的创建线程和销毁线程,可以直接复用已有线程。而我们都知道,创建线程是非常耗时的操作。
提供速度:任务过来之后,因为线程已存在,可以拿来直接使用。
提高线程的可管理性:线程是非常宝贵的资源,如果创建过多的线程,不仅会消耗系统资源,甚至会影响系统的稳定。使用线程池,可以非常方便的创建、管理和监控线程。
当然JDK为了我们使用更便捷,专门提供了:Executors类,给我们快速创建线程池。
该类中包含了很多静态方法:
newCachedThreadPool:创建一个可缓冲的线程,如果线程池大小超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool:创建一个固定大小的线程池,如果任务数量超过线程池大小,则将多余的任务放到队列中。
newScheduledThreadPool:创建一个固定大小,并且能执行定时周期任务的线程池。
newSingleThreadExecutor:创建只有一个线程的线程池,保证所有的任务安装顺序执行。
在高并发的场景下,如果大家使用这些静态方法创建线程池,会有一些问题。
那么,我们一起看看有哪些问题?
newFixedThreadPool:允许请求的队列长度是Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
newSingleThreadExecutor:允许请求的队列长度是Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
newCachedThreadPool:允许创建的线程数是Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
那我们该怎办呢?
优先推荐使用ThreadPoolExecutor类,我们自定义线程池。
ExecutorService threadPool = new ThreadPoolExecutor( |
顺便说一下,如果是一些低并发场景,使用Executors类创建线程池也未尝不可,也不能完全一棍子打死。在这些低并发场景下,很难出现OOM问题,所以我们需要根据实际业务场景选择。
30.Arrays.asList转换的集合别修改
在我们日常工作中,经常需要把数组转换成List集合。
因为数组的长度是固定的,不太好扩容,而List的长度是可变的,它的长度会根据元素的数量动态扩容。
在JDK的Arrays类中提供了asList方法,可以把数组转换成List。
正例:
String [] array = new String [] {"a","b","c"}; |
在这个例子中,使用Arrays.asList方法将array数组,直接转换成了list。然后在for循环中遍历list,打印出它里面的元素。
如果转换后的list,只是使用,没新增或修改元素,不会有问题。
反例:
String[] array = new String[]{"a", "b", "c"}; |
执行结果:
Exception in thread "main" java.lang.UnsupportedOperationException |
会直接报UnsupportedOperationException异常。
为什么呢?
答:使用Arrays.asList方法转换后的ArrayList,是Arrays类的内部类,并非java.util包下我们常用的ArrayList。
Arrays类的内部ArrayList类,它没有实现父类的add和remove方法,用的是父类AbstractList的默认实现。
我们看看AbstractList是如何实现的:
public void add(int index, E element) { |
该类的add和remove方法直接抛异常了,因此调用Arrays类的内部ArrayList类的add和remove方法,同样会抛异常。
说实话,Java代码优化是一个比较大的话题,它里面可以优化的点非常多,我没办法一一列举完。在这里只能抛砖引玉,介绍一下比较常见的知识点,更全面的内容,需要小伙伴们自己去思考和探索。
这篇文章写了很久,花了很多时间和心思,如果你看了文章有些收获,记得给我点赞鼓励一下喔。
bye
 微信
微信 支付宝
支付宝